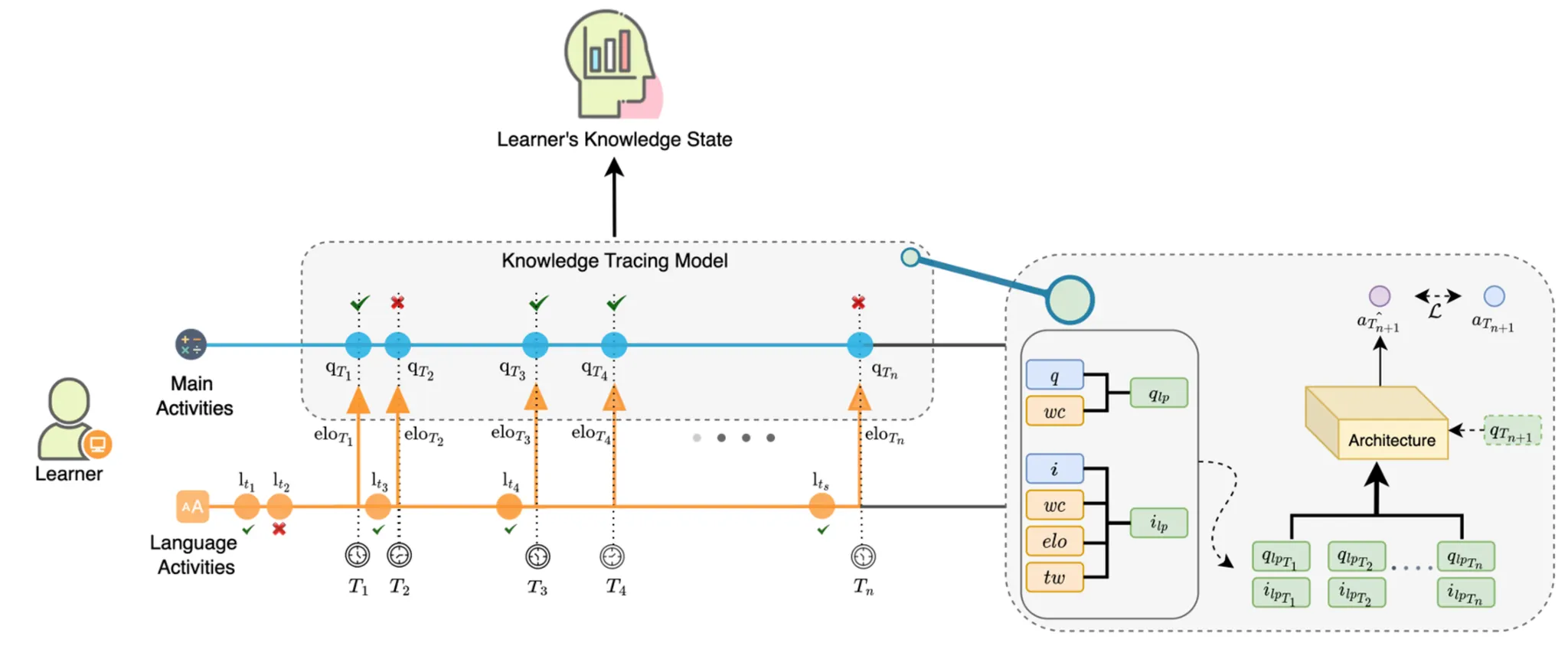
In particular, if we collect problem-solving performance data for students’ first language subjects (e.g., Korean, English, French, etc.), we can estimate their language proficiency (LP) information. LP is an important factor when learners acquire domain knowledge, and it has been shown to have a significant impact on academic performance in a variety of subjects [6,15,30,35]. Moreover, LP is an important factor in the learner’s problem solving. This is owing to the fact that learners must be able to read and comprehend the problem to complete it correctly [6]. For example, in mathematics, students with low LP are known to struggle with long word problems [37]. Therefore, LP information extracted from students’ problem-solving data of language subjects is likely to be useful for the KT task to predict their future performance in other subjects.