

오늘은 교육 전문가들의 의견을 반영하여, 실용적으로 실제 교육 현장에서 활용하기 용이한 학습 성취 예측 방법을 제안한 연구를 소개하도록 하겠습니다.
학습 성취 예측에 대한 선행 연구들
학생의 학습 성취를 미리 예측할 수 있다면, 적절한 교육적인 조치를 취함으로써 학습의 효과를 높이는 데 기여할 수 있습니다. 이러한 기대 하에 학생의 학습 성취를 예측하기 위한 연구들이 오랜 시간 꾸준히 진행되어 왔습니다. 학습자 해당 분야에 대한 선행 연구들을 분석하면 다음과 같은 특징을 발견할 수 있습니다.
•
데이터가 수집된 강좌의 수가 연구마다 다양합니다. 하나의 강좌로부터 데이터를 수집한 경우도 있고, 많게는 700개에 가까운 강좌로부터 데이터를 수집한 경우도 있습니다.
•
다양한 머신러닝 알고리즘이 사용됩니다. 공통적으로 많이 사용되는 알고리즘으로는 decision tree (DT), Naïve Bayes (NB), multi-layer perceptron (MLP), support vector machine (SVM), logistic regression (LR), random forest (RF), and K-nearest neighbor (KNN) 등이 있으며, 앙상블 기법도 많이 사용됩니다.
•
‘위험군’을 예측하는 task의 경우, 위험군을 정의하는 방식이 다양하게 존재합니다. 예를 들어, 특정 학점을 기준으로 위험군을 정의하기도 하고(예: C학점 이하), 전체 수강 학생들의 평균 점수를 기준으로 위험군을 정의하기도 합니다.
•
모델 학습에 사용되는 속성에 대한 교육적인 배경 이론이 다양합니다. 주로 사용되는 배경 이론으로는 Moore의 상호작용 이론, 구성주의 이론, 자기 주도 학습 이론 등이 있습니다.
•
모델 학습에 사용되는 속성들을 선정하는 과정에 큰 관심을 두지 않는 경우가 많습니다. 해당 과정에 대해 설명한 연구들의 경우 상관관계 분석을 이용하거나, 선행 연구들을 참조한 경우가 많습니다.
오늘 소개드릴 연구에서는, 이렇게 꾸준히 진행되어 온 학습 성취 예측 기술에 대해 한 가지 의문을 제기합니다. “과연 이 기술들을 실제 교육 현장에서 사용할 수 있을까?”
실용적인 속성 정의
해당 연구에서는 교육 현장에서 실용적으로 사용될 수 있는 학습 성취 예측 기술을 제안하기 위해, 다음과 같은 네 가지 단계로 feature selection을 합니다.
1.
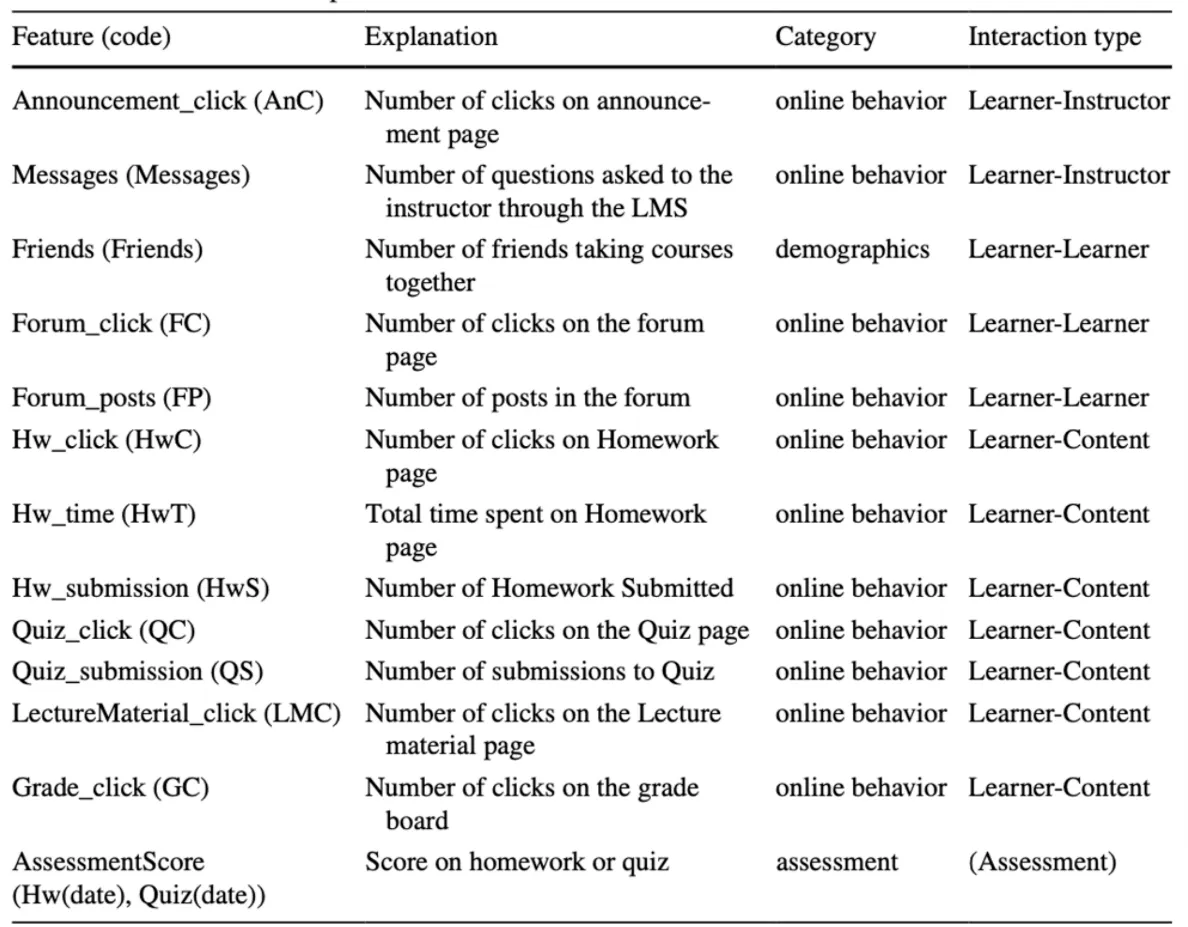
선행 연구 분석: 50개의 선행 연구 분석을 통해, 관련 task에서 사용될 수 있는 속성들을 크게 다섯 가지의 카테고리(학생의 인구통계적 정보, 과거 학교급에서의 학습 성취, 온라인 행동 양식, 학습 관련 내적 속성, 해당 강좌에서의 평가 점수)로 분류합니다.
2.
교육 현장의 이해관계자 그룹 인터뷰: 교육 현장의 이해관계자들의 포커스 그룹 인터뷰 결과 다음과 같은 의견들이 수집되었습니다.
주제 | 의견 요약 |
기술의 효과성 | 학생의 가정 환경에 개입하는 것의 어려움 |
학생의 온라인 행동 양식(예: 퀴즈 페이지의 접속 횟수 등)과 관련하여 교육적 조치를 취하는 것의 어려움 | |
과거 학교급의 학습 성취(예: 중학교에서의 내신 성적 등)에 대한 교육적 조치의 어려움 | |
데이터 수집 | 많은 문항으로 구성된 설문을 이용해 데이터를 수집하는 것의 어려움 |
민감한 개인정보(예: 부모의 학력 등)를 포함한 데이터 수집의 어려움 | |
설명가능성의 필요성 | 학습 성취 예측 결과에 대한 근거를 제공하는 것의 필요성 |
맞춤형 교육을 지원하는 도구로서의 가능성 |
3.
전문가 협의: 포커스 그룹 인터뷰에서의 결과를 바탕으로, 선행 연구에서 사용되었던 속성들 중 교육 현장에서 실용적으로 사용되기 어려운 속성들을 제거하였습니다. 또한 각 속성들을 설명할 수 있는 교육적인 배경 이론으로 Moore의 상호작용 이론을 선정합니다.
4.
상관관계 분석
위의 네 단계의 과정을 거쳐, 연구에서는 다음과 같은 실용적인 속성들을 정의합니다.
실험
데이터셋
K 대학교의 2021-2022학년도의 7개 강좌의 940명에 대한 LMS 데이터를 이용하였습니다.

머신러닝 알고리즘
각 강좌를 수강하는 학생들 중 전체 학생들의 평균 점수 미만의 성적을 보인 수강생을 ‘위험군’으로 분류하고, 위험군 학생들을 예측하는 task를 하기 위해 다음과 같은 머신러닝 알고리즘이 사용되었습니다. 전반적으로, 전통적인 머신러닝 모델들과 최근 주목받는 앙상블 기법들이 사용되었습니다.
•
Logistic Regression (LR)
•
Decision Tree (DT)
•
Multilayer Perceptron (MLP)
•
Support Vector Machine (SVM)
•
Random Forest (RF)
•
XGBoost (XGB)
•
LightGBM (LGBM)
•
Voting Classifier (VTC)
•
Stacking Classifier (STC)
실험 결과
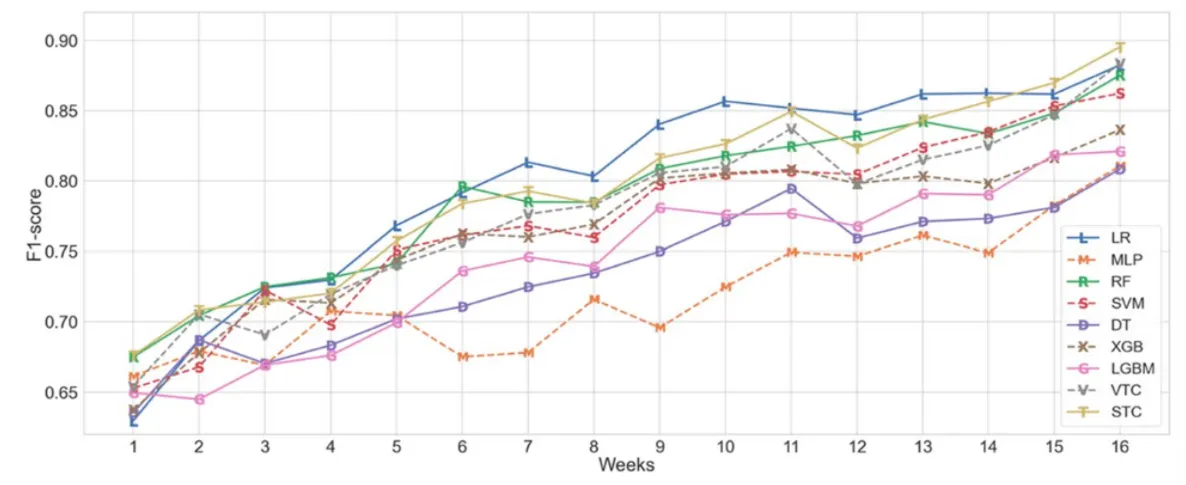
AUC, F1-score 결과는 아래와 같습니다.
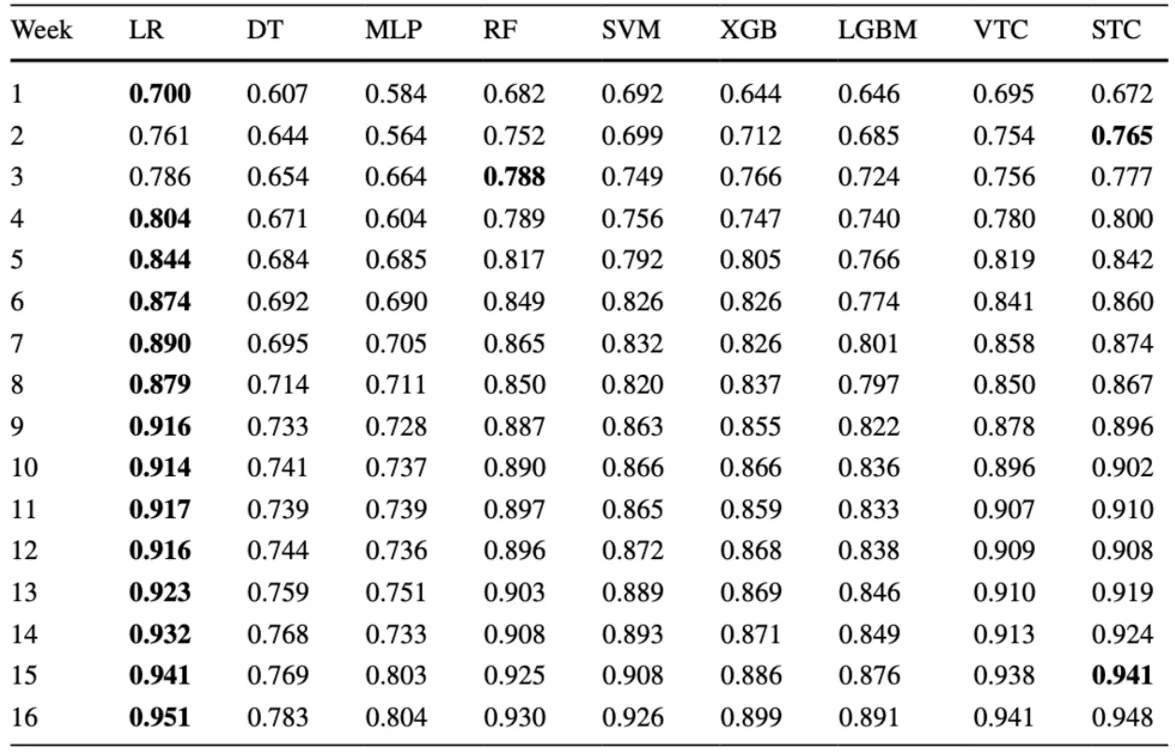
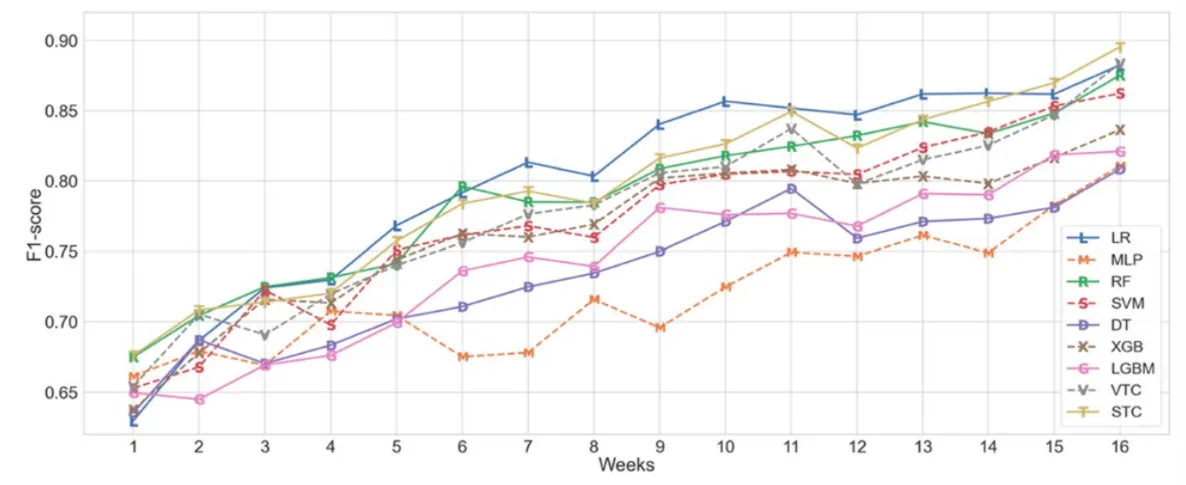
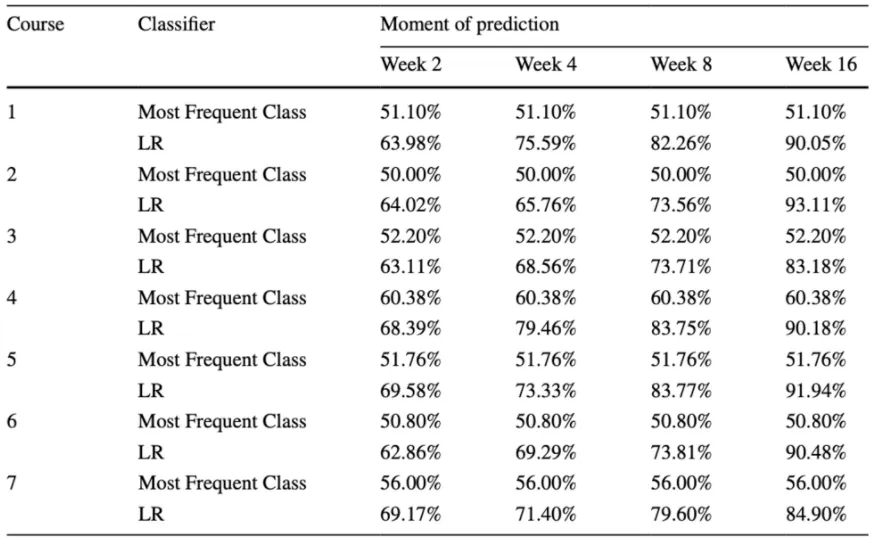
AUC와 F1-score를 전반적으로 고려했을 때 가장 우수한 성능을 보인 logistic regression의 실험 결과를 각 코스별 most frequent class의 비율과 비교한 결과는 아래와 같습니다.
분류 결과에 대한 설명 가능성 부여
머신러닝 분류 결과에 대한 설명이 필요하다는 교육 이해관계자들의 요구를 반영하기 위하여, 설명가능한 인공지능(eXplainable AI, XAI) 기법들 중 SHAP을 선정합니다.
SHAP이란?
협력적 게임이론에 토대를 둔 분배이론인 로이드 섀플리의 섀플리값(Shapley value)을 덧셈연산(additive)이 가능하게 확장한 기법입니다. SHAP을 활용하면 개별 예측(또는 모델 전체)에 대해 각 특성의 값(또는 각 특성)이 어떻게 기여를 했는지 알 수 있게 됩니다. 아래는 해당 연구에서 SHAP을 활용한 예시입니다.
설명 가능성 부여 결과
•
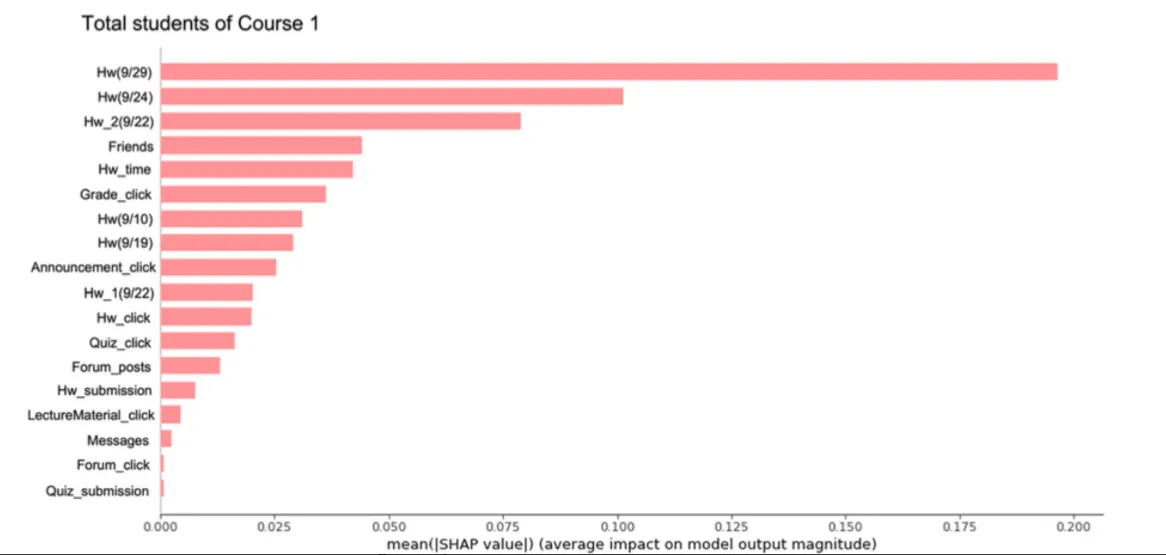
global explanation 결과
강좌1을 수강하는 전체 학생들의 분류 결과에 대한 설명(global explanation)은 아래와 같습니다. 강좌1 수강생들의 위험군 판단에는 9/29 과제 성적(Hw 9/29)이 가장 큰 영향을 미쳤으며, 퀴즈 제출 횟수(Quiz_submission)가 가장 미미한 영향을 미친 것을 알 수 있습니다.
•
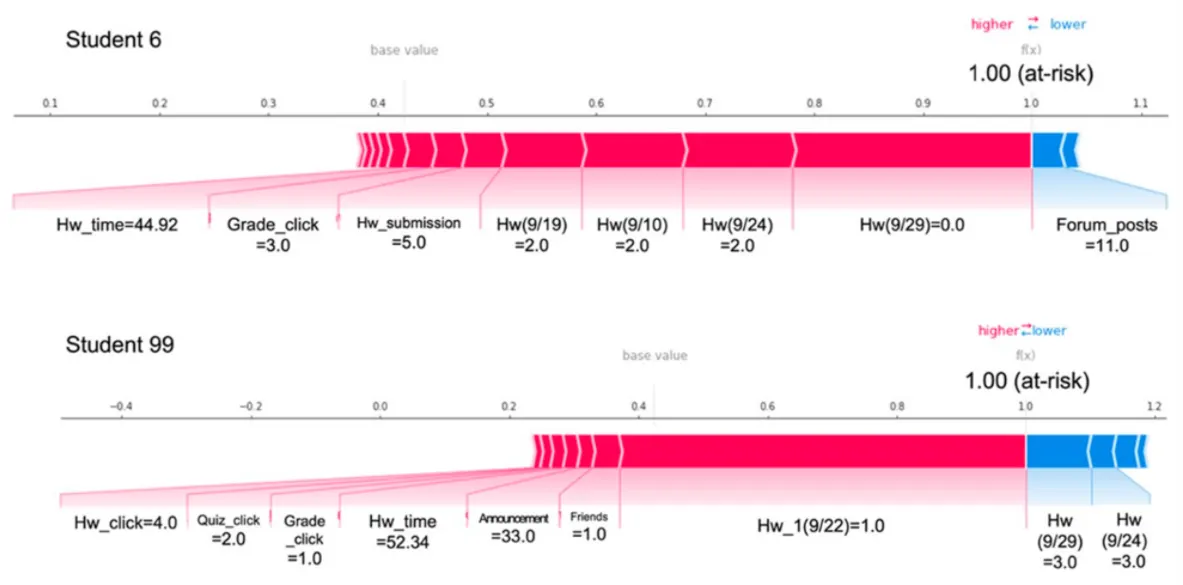
local explanation 결과
강좌1을 수강한 샘플 학생(6번, 99번) 학생의 분류 결과에 대한 설명(local explanation)은 아래와 같습니다.
그림에서 붉은색으로 표시된 부분은 해당 학생이 위험군으로 판단되는 데 정적(+) 영향을 미친 요소를 의미하며, 그래프에서 차지하는 길이가 길수록 더 큰 영향을 미쳤다는 것을 뜻합니다. 반대로 파란색으로 표시된 부분은 해당 학생이 위험군으로 판단되는 데 부적(-) 영향을 미친 요소를 의미하며, 길이가 길수록 더 크게 영향을 미쳤음을 뜻합니다.
예를 들어, 아래 그림에서 6번과 99번 학생은 모두 위험군으로 예측된 학생들입니다. 6번 학생의 경우, 9/29일 과제 성적을 잘 못받은 것이 위험군 판단에 가장 크게 영향을 미쳤으며, 9/24 과제 성적은 그 다음으로 영향을 미쳤습니다. 이 결과는 이 강좌를 수강한 전체 학생들에 대한 global explanation의 결과와 비슷한 맥락을 보입니다.
반면 99번 학생의 경우, 똑같이 위험군으로 예측되었으나 예측된 이유는 6번 학생과 매우 다른 양상을 보입니다. 99번 학생의 경우, 9/29 과제와 9/24 과제에서 좋은 성적을 받았음에도 불구하고 9/22 과제의 성적과 함께 수강하는 친구의 수 등으로 인해 위험군으로 판단되었습니다. 이는 global explanation 결과와 다른 맥락을 가진 학생이 존재함을 보여줍니다.
이로부터 전체 수강생에 대한 global explanation과 함께 각 학생별 local explanation을 활용할 때, 각 학생에게 필요한 맞춤형 교육적 조치를 제공할 수 있는 가능성을 엿볼 수 있습니다.
결론
LMS에서의 학습자 행동 데이터를 기반으로 한 학습 성취 예측은 꾸준히 연구되어온 분야입니다. 오늘 소개드린 연구에서는 특히 교육 현장에서 실용적으로 활용이 가능한 속성들을 정의하고, 설명 가능한 인공지능 기술을 적용하여 각 학생의 진단 결과에 대한 해석을 제공했다는 데 의의가 있습니다.
[references]
Jang, Y., Choi, S., Jung, H. et al., Practical early prediction of students’ performance using machine learning and eXplainable AI. Educ Inf Technol 27, 12855–12889 (2022).
Lundberg, S. M., & Lee, S. I. (2017). A unified approach to interpreting model predictions. Advances in neural information processing systems, 30

저자 정희석 (Heeseok Jung)
고려대학교에서 컴퓨터학 전공으로 학,석사학위를 취득 후, 현재 CT AI Researcher로 재직중이다. 추천 시스템, 지식추적 등과 같은 AIEd에 관심을 가지고 연구하고 있다.
poco2889@classting.com