

Data matters. Accordingly, data augmentation has been an important ingredient for boosting performances of learned models. Prior data augmentation methods for few-shot text classification have led to great performance boosts. However, they have not been designed to capture the intricate compositional structure of natural language. As a result, they fail to generate samples with plausible and diverse sentence structures. Motivated by this, we present the data augmentation using lexicalized probabilistic context-free grammars that generates augmented samples with diverse syntactic structures with plausible grammar.
The Lexicalized PCFG parse trees consider both the constituents and dependencies to produce a syntactic frame that maximizes a variety of word choices in a syntactically preservable manner without specific domain experts. Experiments on few-shot text classification tasks demonstrate that ALP enhances many state-of-the-art classification methods.
We delve into the train-val splitting methodologies when a data augmentation method comes into play. We argue empirically that the traditional splitting of training and validation sets is sub-optimal compared to our novel augmentation-based splitting strategies that further expand the training split with the same number of labeled data. Taken together, our contributions on the data augmentation strategies yield a strong training recipe for few-shot text classification tasks.
Using Self-Training for Learning with limited data?
Due to the high acquisition cost of labeled data, semi-supervised learning is in demand for natural language processing tasks. Self-training, one of the earliest semi-supervised methods, has led to significant improvements in text classification when there is a limited number of labeled data. Self-training uses a teacher model trained from the labeled data and creates pseudo-labels for unlabeled data, which are often larger than the labeled data.

Teacher Model Optimization
Pseudo-Label Generation
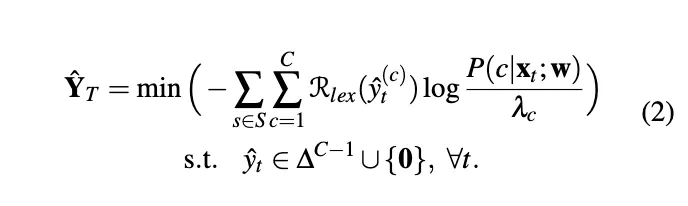
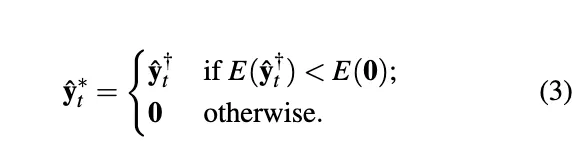
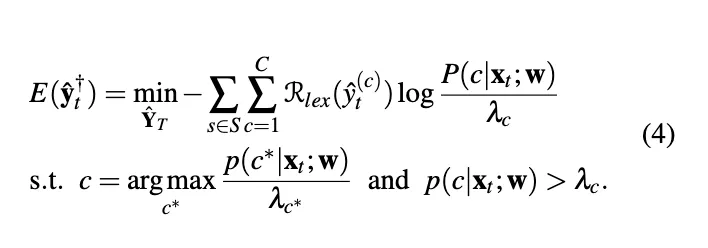
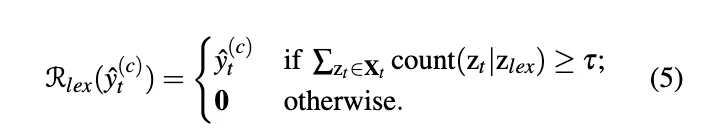
Confidence Regularization with Lexicon Words
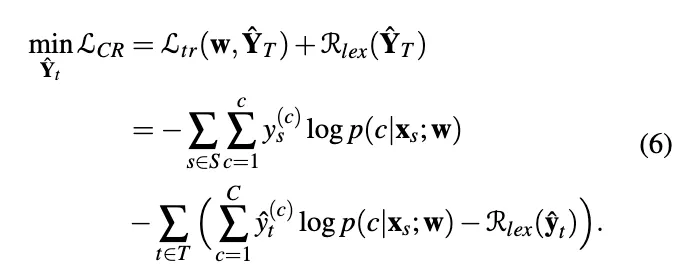
Data Augmentation with Lexical Knowledge
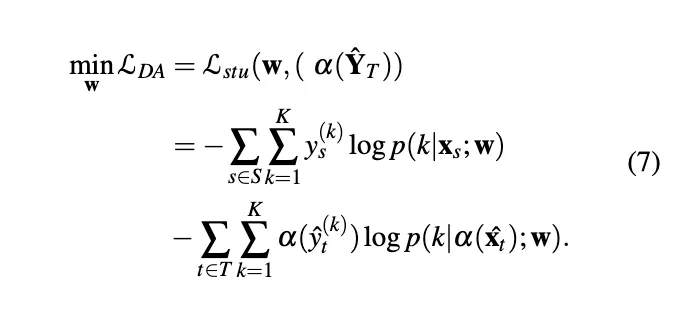
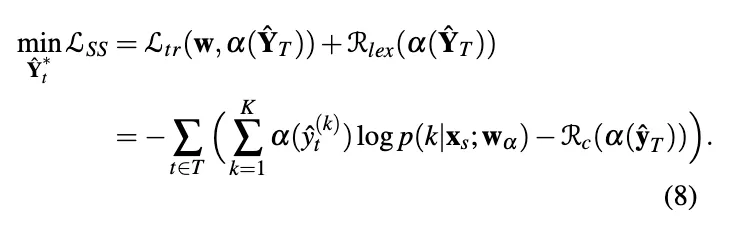

More analysis about syntactic correctness or semantic preservation? Different measurement than type token ratio or n-gram to show diversity?
Our method guarantees syntactic correctness as long as the neural parser we adopt to extract parse trees produces accurate syntactic information.
ALP generates sentences with decent semantic fidelity, as shown in the table below. We use a BERT-Base classifier fine-tuned on all available labeled samples to measure classification accuracies on generated data. Higher scores indicate the preservation of class labels in generated data. ALP has fidelity scores (81.8) closest to the original (85.2).
Our measurement of \textbf{text diversity} based on the ``type-token ratio'' has been inspired by [a], who also measured the text diversity. However, we agree with the reviewers that this measurement alone may be misleading. We thus introduce additional measurements based on the Self-BLEU scores [b] that assess how an augmented sentence resembles the original one. In the below table, ALP shows the lowest Self-BLEU scores, which imply high diversity of the text.

Actual number of training examples from different augmentation methods?
200 samples in total for all augmentation methods.
The improvements in Table below are not that great and the standard deviations are also very large?
The relatively large standard deviations are inevitable for the few-shot learning setting because of the huge variance in qualities of the few samples. It is not the methods but the task that generates the noise. Given this limitation, we have put the best efforts to reduce the additional noise through 5 repeated experiments and transparently report the error bars.
See the barplot visualization of Table below (best viewed in color). It is important to note that ALP's superiority is consistent across all 4 benchmarks. It is highly unlikely that a sub-optimal method outperforms baselines on all benchmarks, albeit with large individual error bars.

How ALP scales down with resource availability?
The most resource-demanding part of the ALP algorithm is the neural parser. We used the Berkeley Neural Parser. It parses sentences in a reasonable time even with only CPUs.
Is ALP English specific?
The only component of ALP that is hard-coded to English is the neural parser. Since, for example, the Berkely Neural Parser commonly used neural parser supports 10 other languages than English, we believe it should be possible in principle to extend ALP to those languages.
References
ALP: Data Augmentation Using Lexicalized PCFGs for Few-Shot Text Classification, AAAI2022
LST: Lexicon-Guided Self-Training for Few-Shot Text Classification, ArXiv2022

저자 김현지 (Hazel Kim)
연세대학교에서 인공지능 전공으로 석사 학위를 취득했으며, 현재 CT AI Researcher로 재직중이다. 관심 연구 분야는 자연어처리, 제한된 데이터 기반 학습, 언어모델의 불확실성 및 통제가능성 연구 등이다.