
Personality detection identifies a person's characteristic patterns in the online text he or she creates. Active participants on social media yield a considerable amount of online posts implying their psychological status. Having emerged personalized systems using online postings, natural language processing tasks requires psycholinguistic knowledge to detect individuals' personality traits. This emerging task is currently in demand for extensive application scenarios such as personalized recommendation systems, dialogue systems, and more.
Yet prior personality detection has been under-explored and restricted. Existing methods require resource-intensive and time-consuming professional tags to infer personality traits using ground-truth information. Those using deep neural networks have still focused on extra resources of lexical features in addition to the labeled training data. The performance heavily relying on such manual resources as Linguistic Inquiry and Word Count (LIWC) and Medical Research Council (MRC) restricts the pre-trained model's psycholinguistic proficiency and constrains the method in words only specified in the dictionaries. Not only utilizing the dictionaries but pre-trained language models are not in proper use.
We have three assumptions regarding pre-trained language models (PLMs) to minimize these issues. First, personality detection methods utilizing pre-trained language models (PLMs) rely on shortcutted lexical cues than understanding the knowledge in texts. Second, those lexical cues harm PLMs to perform well on out-of-distribution or unseen examples. Third, PLMs are capable of acknowledging the causal relations across out-of-distribution datapoints. We aim to generalize models well to unseen data by inducing models to emerge relevant knowledge through causal relations
What is Personality Detection?
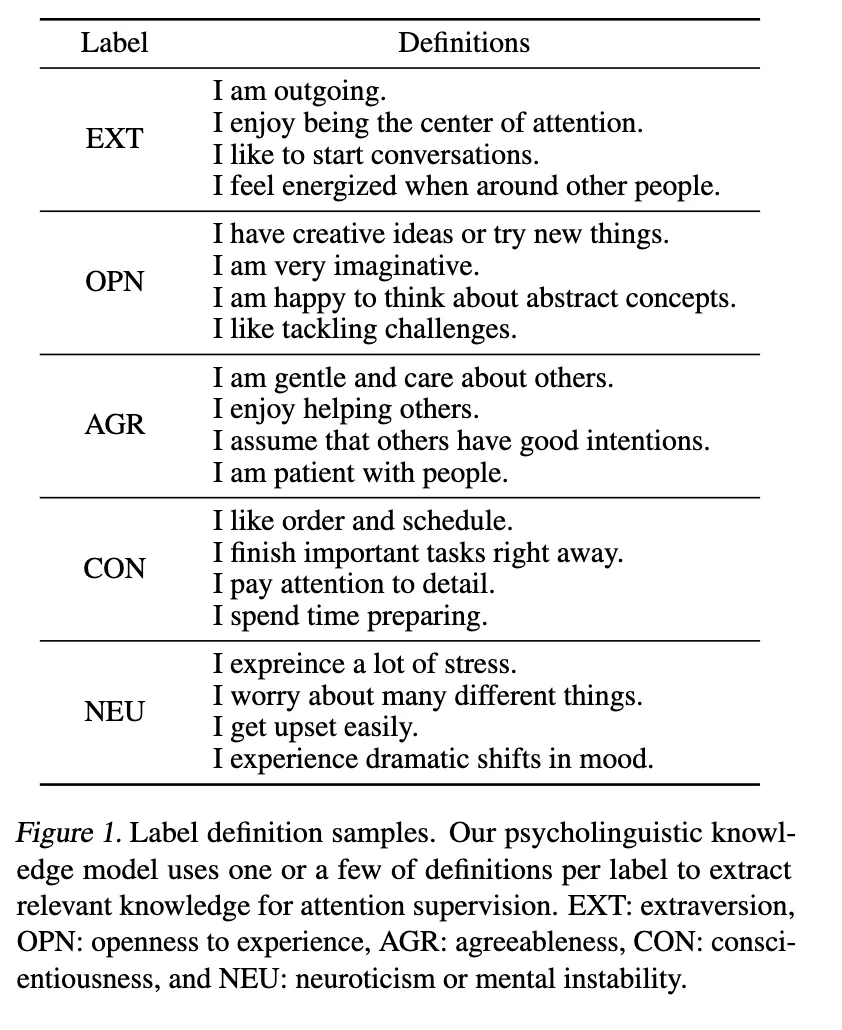
Most work on personality detection studies the model performance with an evaluation metric such as Big Five models. The Big Five models utilize four different psychological attributes of analyzing how one gains energy (extraversion), how one processes information (openness to experience), how one makes decisions (agreeableness), and how one presents themselves to the outside world (conscientiousness), and how one he feels anxiety and depression (neuroticism).
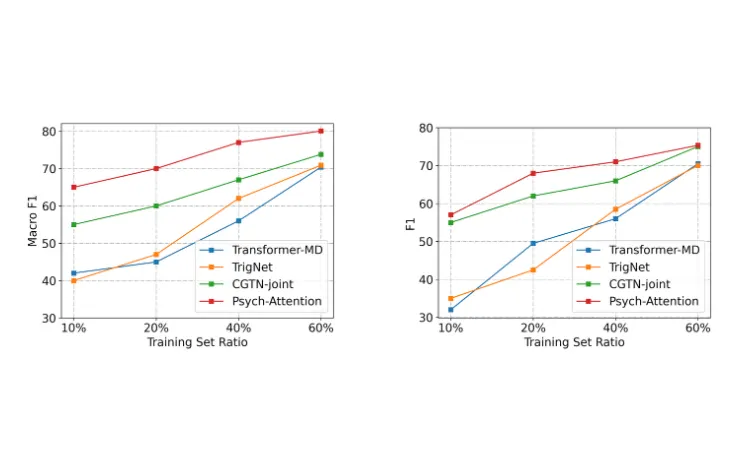
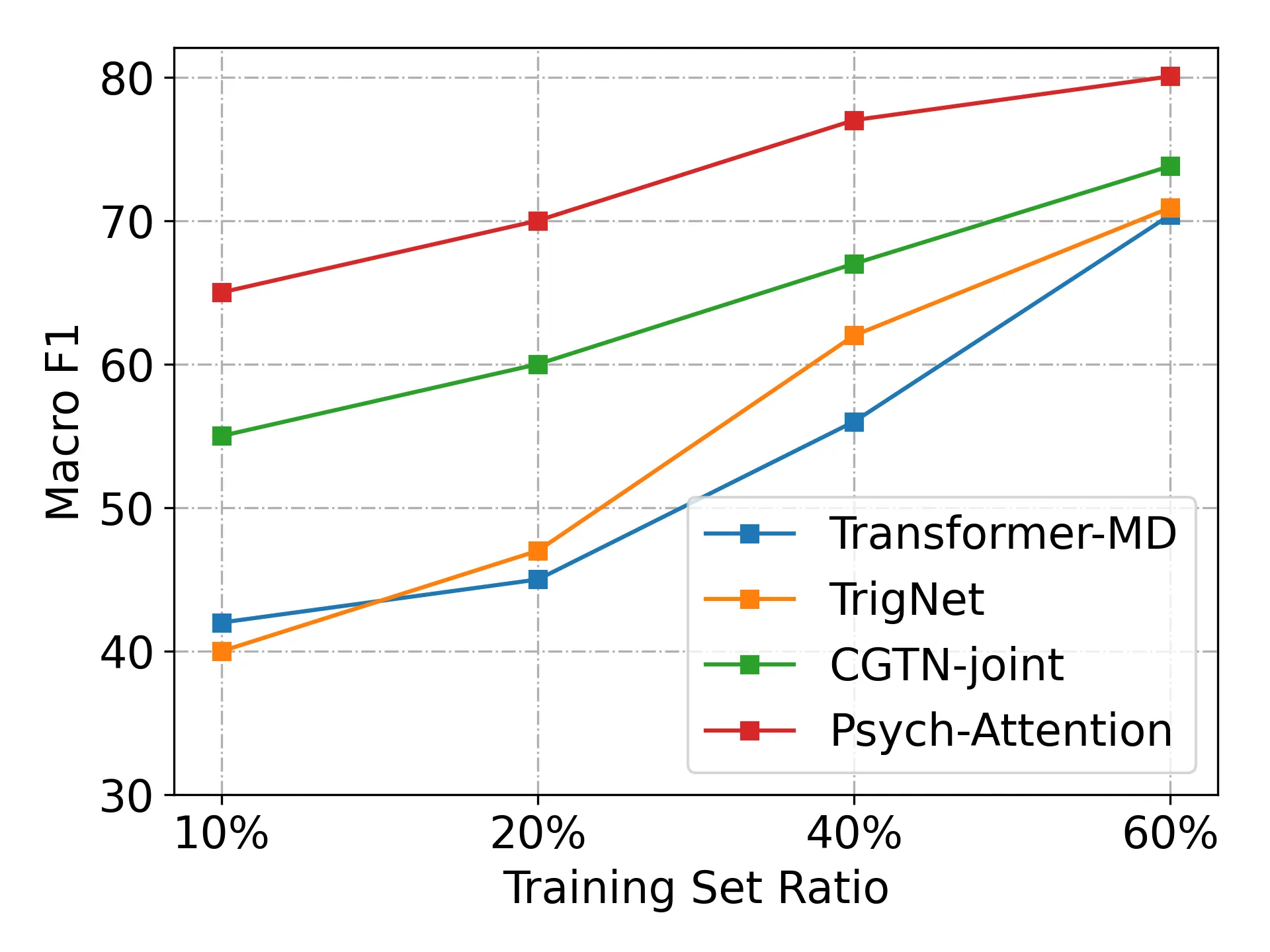
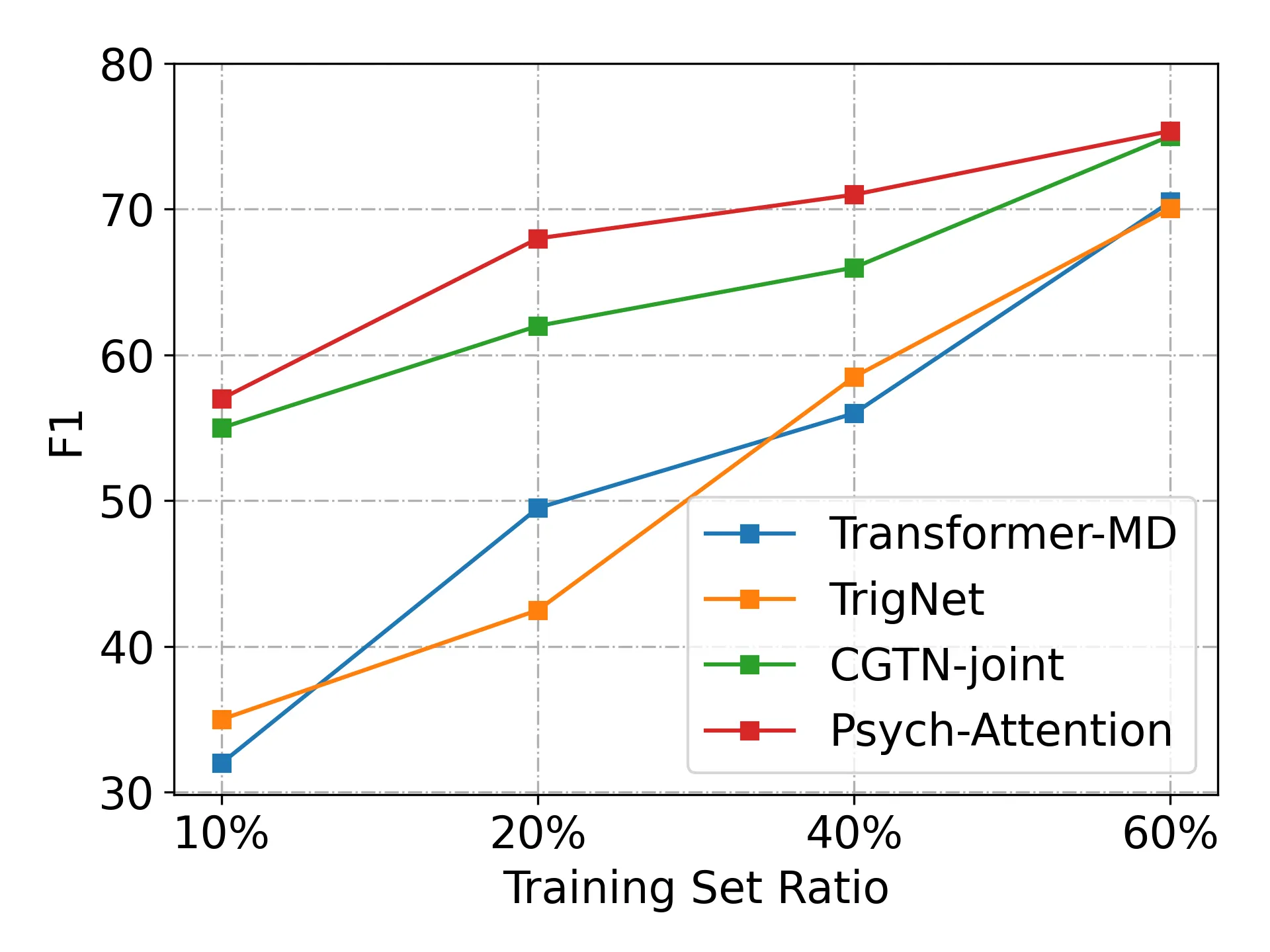
Performance Depending on Training Set Ratios?
We observe that the number of label definitions does not produce huge impact on ultimate performances once the solid definition implying valid psycholinguistic knowledge is provided for generating our desired attention maps as shown. We also compare our approach with three baseline models to evaluate the robustness in low-resource settings. We set 10%, 20%, 40%, and 60% of training sets respectively to evaluate our strong performances in various low-resource settings. Following the prior work, we run our approach 10 times with different seed numbers and observe the best performances overall settings.
We have proposed a personality detection method that improves model performances in limited resource settings without expensive external resources such as Linguistic Inquiry and Word Count (LIWC) to obtain psycholinguistic information. We self-supervise the model with significantly less annotation cost for personality cues. Extensive experiments have demonstrated the effectiveness of attention supervision with psycholinguistic features extracted from the pre-trained language models for personality detection. Classting AI Research would keep in working on personality detection tasks for better personalized systems for students and teachers, those utilizing our software systems for their academic journeys.

저자 김현지 (Hazel Kim)
연세대학교에서 인공지능 전공으로 석사 학위를 취득했으며, 현재 클래스팅 AI Researcher로 재직중이다. 관심 연구 분야는 자연어처리, 제한된 데이터 기반 학습, 언어모델의 불확실성 및 통제가능성 연구 등이다.